第14章 一般種法による超超高速魔方陣自動生成
第2話 一般種の商を生成
を実現するコード例
マルチスレッド版数独自動生成ソフトC++コードを題材とする超初心者のためのVisual Studio C++講義
第14章 一般種法による超超高速魔方陣自動生成
第2話 一般種の商を生成
を実現するコード例
#pragma warning(disable: 4996)//第2編のために必要
#include<iostream>//インクルードファイルiostreamの読み込み
#include<conio.h>//while(!_kbhit());を使うためのお呪い
#include<string> //文字列変数を使えるようにするために組み込む
#include <iomanip> //setprec商ionを使えるように組み込む
#include <cmath>//powなどを使うときに必要
#include <ctime>//time()(←現時刻発生する関数)を使うために必要
#include <windows.h>
#include <process.h>//_beginthreadを使うために必要
using namespace std;//coutを使うときに必要なお呪い
void 変身の術関数(void* aa);//スレッドを派生させる関数
const size_t n = 6;
const size_t th = n * n;
const size_t ts = 100;
void tanez(size_t p, size_t s, size_t 商[n][n], size_t 前半回数[th][n]);//一般種商
void 2次座標生成();
size_t 商累積[ts][n][n];//魔方陣を収納する2元配列
size_t cn = 0;//それぞれのスレッドにおける魔方陣をカウントする変数
size_t y[th];//縦座標
size_t x[th];//横座標
size_t b[n][n];//y座標・x座標形成のための2次元配列
size_t mg = n * (th + 1) / 2;//魔方陣の対角線または行または列の合計
size_t ps;//魔方陣を発見したスレッドの番号を保存する変数
size_t 継続 = 1;
size_t シード値 = (unsigned)time(NULL);
//size_t h2[th][th];//候補数字ランダム順
//size_t h1[th];//昇順
//size_t mx[th];//候補数字数
size_t ig = n * (n - 1) / 2;//一般種の対角線または行または列の合計
int main() {
clock_t hj, ow;
2次座標生成();
hj = clock();
cout << "マルチスレッド版" << n << "次魔方陣生成を始めます。" << endl;
size_t i2[th];
for (size_t i = 0; i < th / 3; i++) {
i2[i] = i;
_beginthread(変身の術関数, 0, &i2[i]); //新しいスレッドを起動して、そのスレッド上で関数問題生成関数を働かせなさいの命令
}
while (継続) {}
ow = clock();
cout << endl;
size_t 個数 = 0;
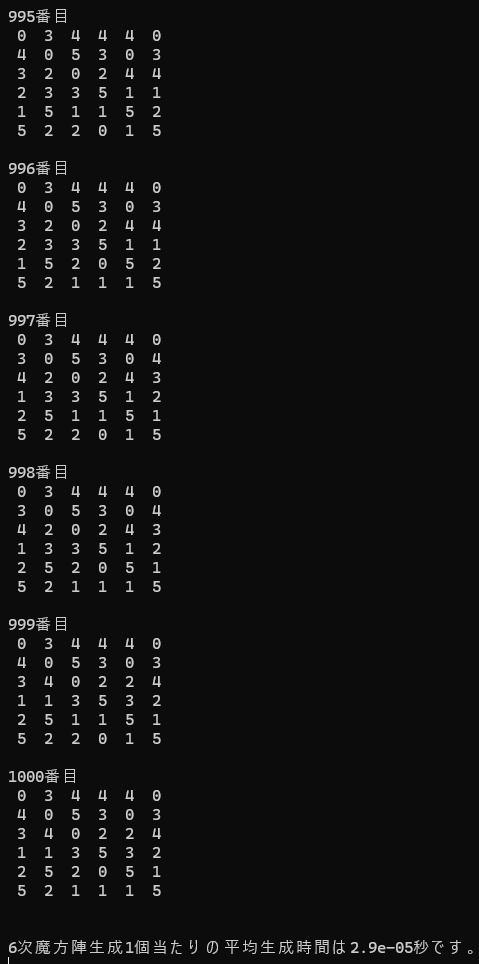
for (size_t p = 0; p < ts; p++) {
cout << p + 1 << "番目" << endl;
for (size_t i = 0; i < n; i++) {
for (size_t j = 0; j < n; j++) {
if (商累積[p][i][j] < 10) {
cout << " " << 商累積[p][i][j] << " ";
}
else {
cout << 商累積[p][i][j] << " ";
}
}
cout << endl;
}
cout << endl;
}
cout << endl;
cout << n << "次魔方陣生成1個当たりの平均生成時間は" << (double)(ow - hj) / (ts * CLOCKS_PER_SEC) << "秒です。" << endl;
while (!_kbhit());//待機させるための命令
return(0);
}
void 変身の術関数(void* aa) {//マルチスレッド
size_t p = *(size_t*)aa;//スレッド番号=異世界番号
srand(シード値 - 19 * p);
size_t 商[n][n];
size_t 前半回数[th][n];
//直交初期化
for (size_t i = 0; i < th; i++) {
for (size_t j = 0; j < n; j++) {
前半回数[i][j] = 0;
}
}
tanez(p, 0, 商, 前半回数);
}
void tanez(size_t p, size_t s, size_t 商[n][n],size_t 前半回数[th][n]) {//一般種商生成関数
//商解析
size_t 始め = p / n;
for (size_t i = 0; i < n; i++) {
size_t h;
size_t Y;
Y = (始め + i) % n;
商[y[s]][x[s]] = Y;
h = 1;
if (前半回数[p][Y] >= n)h = 0;
前半回数[p][Y]++;
size_t gk;
if (y[s] == n - 1 && x[s] == n - 1) {
gk = 0;
for (size_t j = 0; j < n; j++)gk += 商[j][j];
if (gk != ig)h = 0;
}
if (継続 == 0)return;
if (h == 1) {
if (y[s] == n - 1 && x[s] == 0) {
gk = 0;
for (size_t j = 0; j < n; j++)gk += 商[j][n - 1 - j];
if (gk != ig)h = 0;
}
}
if (継続 == 0)return;
if (h == 1) {
if (y[s] == 0 && x[s] == n - 2) {
gk = 0;
for (size_t j = 0; j < n; j++)gk += 商[y[s]][j];
if (gk != ig)h = 0;
}
}
if (継続 == 0)return;
if (h == 1) {
if (y[s] > 0 && y[s] < n - 1 && x[s] == n - 1) {
gk = 0;
for (size_t j = 0; j < n; j++)gk += 商[y[s]][j];
if (gk != ig)h = 0;
}
}
if (h == 1) {
if (y[s] == n - 2 && x[s] == 0) {
gk = 0;
for (size_t j = 0; j < n; j++)gk += 商[j][x[s]];
if (gk != ig)h = 0;
}
}
if (継続 == 0)return;
if (h == 1) {
if (y[s] == n - 2 && x[s] == n - 1) {
gk = 0;
for (size_t j = 0; j < n; j++)gk += 商[j][x[s]];
if (gk != ig)h = 0;
}
}
if (継続 == 0)return;
if (h == 1) {
if (y[s] == n - 1 && x[s] > 0 && x[s] < n - 1) {
gk = 0;
for (size_t j = 0; j < n; j++)gk += 商[j][x[s]];
if (gk != ig)h = 0;
}
}
if (継続 == 0)return;
if (h == 1) {
if (y[s] == n - 1 && x[s] == n - 2) {
gk = 0;
for (size_t j = 0; j < n; j++)gk += 商[y[s]][j];
if (gk != ig)h = 0;
}
}
if (h == 1) {
if (s + 1 < th) {
tanez(p, s + 1, 商, 前半回数);
if (継続 == 0)return;
}
else {
for (size_t j = 0; j < n; j++) {
for (size_t k = 0; k < n; k++) {
商累積[cn][j][k] = 商[j][k];
}
}
InterlockedIncrement((volatile LONG*)&cn);
if (cn == ts) {
継続 = 0;
return;
}
}
}
前半回数[p][Y]--;
if (継続 == 0)return;
}
}
void 2次座標生成() {//y横座標とx縦座標生成
int i, j, c;
for (i = 0; i < n; i++) {
for (j = 0; j < n; j++) {
b[i][j] = -1;
}
}
for (i = 0; i < n; i++) {
b[i][i] = i;
}
c = n - 1;
for (i = 0; i < n; i++) {
if (b[i][n - 1 - i] == -1) {
c++;
b[i][n - 1 - i] = c;
}
}
for (i = 0; i < n; i++) {
for (j = 0; j < n; j++) {
if (b[i][j] == -1) {
c++;
b[i][j] = c;
}
}
}
for (i = 0; i < n; i++) {
for (j = 0; j < n; j++) {
x[b[i][j]] = j;
y[b[i][j]] = i;
}
}
}
これでも充分高速ですが、
実は全体構造解析型が可能です。
6次魔方陣の場合
for (size_t i = 0; i < n; i++) {
から常に選択肢は6個ですが、第13章第17話で行った全体構造解析をやれば
選択肢は進行と共に6個→5個→4個→3個→2個→1個と減少していきます。
ですから、構造解析型の手法を取り入れてより高速化を図ってください。