を実現するコード主要部分再掲
マルチスレッド版数独自動生成ソフトC++コードを題材とする超初心者のためのVisual Studio C++講義
第13章 様々な魔方陣の作成および自動生成
第18話 全体構造解析のトレース
を実現するコード主要部分再掲
void 変身の術関数(void* aa) {//マルチスレッド
size_t p = *(size_t*)aa;//スレッド番号
srand(シード値 - 19 * p);
size_t k[th];
size_t 配列[th];//候補数字ランダム順
for (size_t i = 0; i < th; i++) {
k[i] = 1;
}
for (size_t i = 0; i < th; i++) {
size_t q;
while (1) {
q = rand() % th;
if (k[q] == 1) {
配列[i] = h1[q];
k[q] = 0;
break;
}
}
}
size_t max = th;
f(p, 0, max, 配列);
}
void f(int p, int s, size_t max, size_t 配列[th]) {//魔方陣生成関数
size_t gz = rand() % max;
for (size_t i = 0; i < max; i++) {
size_t h = 1;
if (継続 == 0)return;
a[p][y[s]][x[s]] = 配列[(i + gz) % max];
size_t u;//交換の受け皿
u = 配列[max - 1];
配列[max - 1] = 配列[(i + gz) % max];
配列[(i + gz) % max] = u;
max--;
if (継続 == 0)return;
if (h == 1) {
if (y[s] == n - 1 && x[s] == n - 1) {
size_t 合計 = 0;
for (size_t j = 0; j < n; j++) {
合計 += a[p][j][j];
}
if (合計 != mg)h = 0;
}
}
if (継続 == 0)return;
if (h == 1) {
if (y[s] == n - 1 && x[s] == 0) {
size_t 合計 = 0;
for (size_t j = 0; j < n; j++) {
合計 += a[p][j][n - 1 - j];
}
if (合計 != mg)h = 0;
}
}
if (継続 == 0)return;
if (h == 1) {
if (y[s] == 0 && x[s] == n - 2) {
size_t 合計 = 0;
for (size_t j = 0; j < n; j++) {
合計 += a[p][y[s]][j];
}
if (合計 != mg)h = 0;
}
}
if (継続 == 0)return;
if (h == 1) {
if (y[s] > 0 && y[s] < n - 1 && x[s] == n - 1) {
size_t 合計 = 0;
for (size_t j = 0; j < n; j++) {
合計 += a[p][y[s]][j];
}
if (合計 != mg)h = 0;
}
}
if (継続 == 0)return;
if (h == 1) {
if (y[s] == n - 2 && x[s] == 0) {
size_t 合計 = 0;
for (size_t j = 0; j < n; j++) {
合計 += a[p][j][x[s]];
}
if (合計 != mg)h = 0;
}
}
if (継続 == 0)return;
if (h == 1) {
if (y[s] == n - 1 && x[s] > 0 && x[s] < n - 1) {
size_t 合計 = 0;
for (size_t j = 0; j < n; j++) {
合計 += a[p][j][x[s]];
}
if (合計 != mg)h = 0;
}
}
if (h == 1) {
if (y[s] == n - 1 && x[s] == n - 2) {
size_t 合計 = 0;
for (size_t j = 0; j < n; j++) {
合計 += a[p][y[s]][j];
}
if (合計 != mg)h = 0;
}
}
if (継続 == 0)return;
if (h == 1) {
if (s + 1 < th) {
f(p, s + 1, max, 配列);
if (継続 == 0)return;
}
else {
for (size_t j = 0; j < n; j++) {
for (size_t k = 0; k < n; k++) {
m[j][k] = a[p][j][k];
}
}
ps = p;
cn++;
if (cn == ts)継続 = 0;
if (継続 == 0) {
a[p][y[s]][x[s]] = 0;
max++;
u = 配列[max - 1];
配列[max - 1] = 配列[(i + gz) % max];
配列[(i + gz) % max] = u;
return;
}
}
}
if (継続 == 0) {
a[p][y[s]][x[s]] = 0;
max++;
u = 配列[max - 1];
配列[max - 1] = 配列[(i + gz) % max];
配列[(i + gz) % max] = u;
return;
}
a[p][y[s]][x[s]] = 0;
max++;
u = 配列[max - 1];
配列[max - 1] = 配列[(i + gz) % max];
配列[(i + gz) % max] = u;
}
}
重要事項を振り返った後で、
極めて長い途程になりますが、
読者のためにトレースをします。
重要事項とは
size_t 配列[th];//候補数字ランダム順
です。[th]はスレッドを表すものではなく 0,1,2,・・・,n - 1 のn通りを表すものです。
グローバル配列にして今う場合には
size_t 配列[th][th];
と2次元配列になってしまいますが、
今回はスレッド側で定義しているので[th]が不要となり1次元配列で済むのです。
おそらく、プログラムコードを簡単にすることと
生成速度の向上に大きく貢献しています。
今までのコードの中にもおそらく3次元から2次元や2次元から1次元に落とせるものもたくさんあると思います。
ぜひ、読み返す際にスレッド側で定義すれば次元が落とせるものがあるかもしれない、
と言う前提のもとに読んでください。
私が示しているコードはただの一例に過ぎないもので、
改善の余地があるのは当然です。
前話で述べた通りプログラミングは無数にあるのです。
ですから、読者自身が工夫をして改良してください。
そして、私のプログラムより高速に生成できた場合は是非連絡してください。
メールアドレス:fmut1621@hotmail.co.jp
そのメールには氏名を載せることが可か不可を記載してください。
可の場合には氏名を載せてそのコードを本講義に載せます。
よろしくお願いします。
では、トレースに入りましょう。
for (size_t i = 0; i < th; i++) {
k[i] = 1;
}
for (size_t i = 0; i < th; i++) {
size_t q;
while (1) {
q = rand() % th;
if (k[q] == 1) {
配列[i] = h1[q];
k[q] = 0;
break;
}
}
}
によって配列の中身は{1,2,3,・・・,36}ではななく
{13,5,18,23,4,10,31,2,21,22,30,7,25,3,8,26,33,15,・・・}
とランダムになっていることに注意が必要です。
size_t gz = rand() % max;とa[p][y[s]][x[s]] = 配列[(i + gz) % max];
探索順を変えるために入れてあります。
例えば gz = 9 であった場合には
(i + gz) % max = 22 (配列番号9は22です)になります。
% maxがあり最初はmax = 36ですから[]の中は10
{22,30,7,25,・・・}となります。
つまり、始める順番をランダム化しているわけです。
一般にはランダムにする方が速くなると言われているからです。
始まりをランダムにすることによってスレッド間の重複の確率は限りなく0%に近づいていきます。
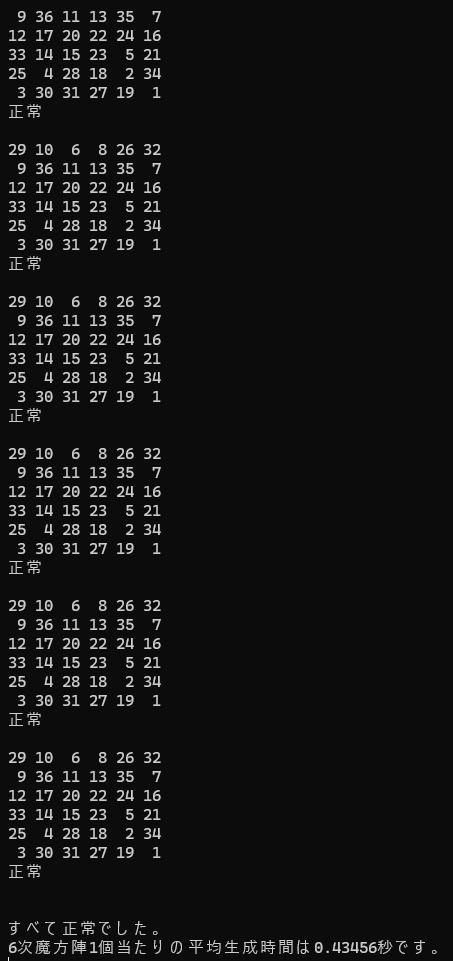
6次魔方陣の36回数字を入れていくのですが、
それがすべて同じになる確率は(1/6)の36乗で0%といってもよいほどです。
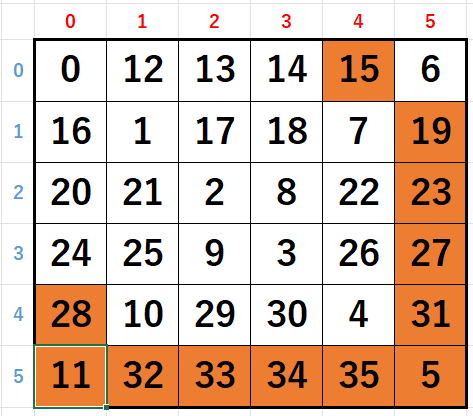
の順に探索して合計がチェックされる場所は上図のオレンジのところですから
(0,0)にが10入り←配列の数字と
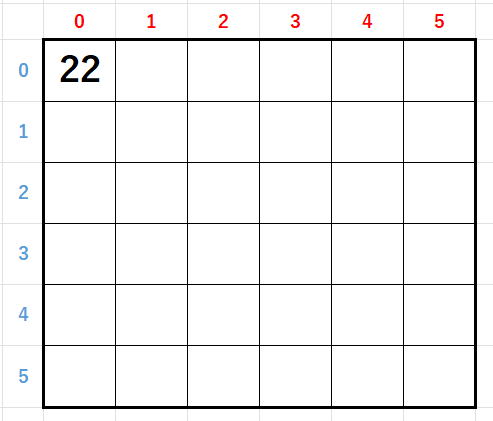 となります。
となります。
その際に
max--;
が働き max = 35 となります。
オレンジではないですから
if (h == 1) {
if (s + 1 < th) {
f(p, s + 1, max, 配列);
によっての1に進みます。
以降ランダムに進みますが、
a[p][y[s]][x[s]] = 配列[(i + gz) % max];
size_t u;//交換の受け皿
u = 配列[max - 1];
配列[max - 1] = 配列[(i + gz) % max];
配列[(i + gz) % max] = u;
max--;
があるために数字の重複はなく、
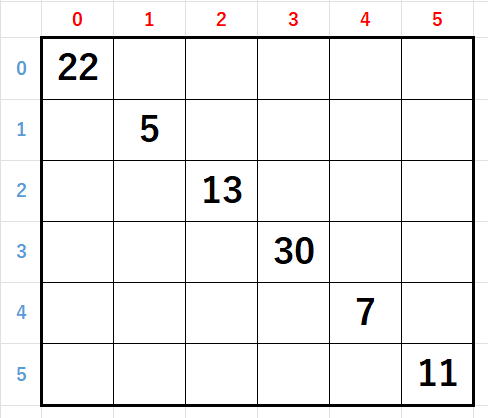
と進みますが、オレンジに達しましたので
対角線合計が計算されますが、残念ながら88で111ではありません。
つまり失敗しているので浮上して合計が111になるまで何回も潜航・浮上を繰り返します。
size_t u;//交換の受け皿
u = 配列[max - 1];
配列[max - 1] = 配列[(i + gz) % max];
配列[(i + gz) % max] = u;
max--;
によって順番を変えられたとしても{}内には必ず1,2,・・・,36の数字が残っていますから、
何回潜航・浮上を繰り返そうとも数字の重複は絶対に起きずに合計値が111になるまで
コンピュータは粘り強く試行錯誤を繰り返して魔方陣を1個当たり0.5秒程度で生成してしまうのです。
トレースを粘り強くやるつもりでしたが、
トレースをやるだけで分厚い本1冊分になってしまいますので、
この後はご自分でトレースをやってください。
さて、これで13章を終了して、第14章では一般種法に入ります。
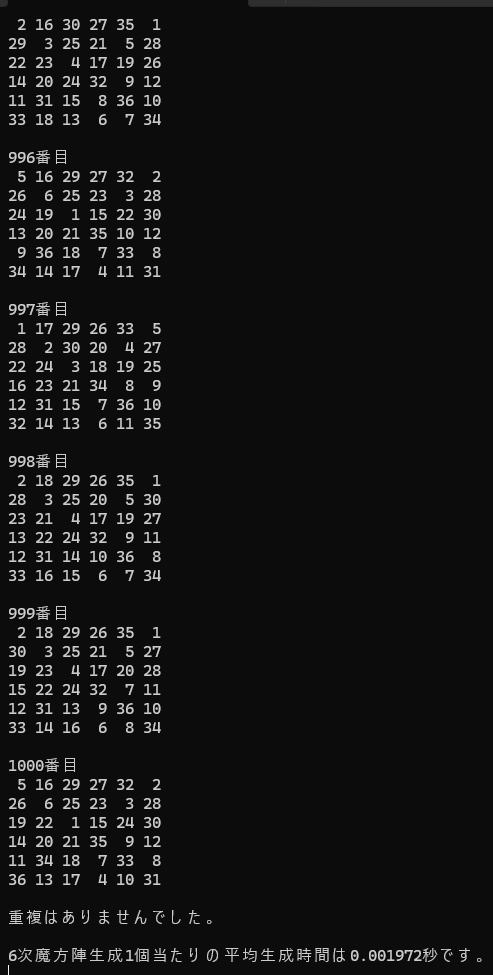 衝撃の結果が待っています。
衝撃の結果が待っています。
全体構造解析型をはるかに上回る生成速度の実現です!
全体構造解析型の0.4356秒も驚異的な数字でしたが、
なんと、0.001972秒です。やく220倍の速さを実現しています。
既存研究では6次魔方陣の1個当たりの生成時間はスパコンを利用しても
数分から数時間だそうですから、仮に2分だとして計算しても
120÷0.001972=約60851倍の生成速度を普通のパソコンで実現できています。
この話を聞くと全体構造解析型の0.4356秒という数字もかなり驚愕の数字だった訳です。
既存研究の120÷0.4356=約275倍生成速度を実現しています。
スパコンとパソコンの速度比を考えると少なく見積もっても2750000倍の生成速度を実現している可能性があります。
自分で成功した方は大いに自信をもって良い結果です。
さらに、一般種法に成功すると既存研究の608510000倍を実現している可能性があります。
読者の皆さんは一端の魔方陣研究者になっているのかもしれませんね(笑)。
一般種法とはいったいどんな方法なのでしょうか。
第13章第17話へ 第14章1話へ
本講義トップへ