マルチスレッド版数独自動生成ソフトC++コードを題材とする超初心者のためのVisual Studio C++講義
第10章 関数の再帰的使用によって魔方陣を自動生成する
第5話 仮屋崎さんの天才的方法解説に入る前の予備知識(構造化プログラミングの思想)
(
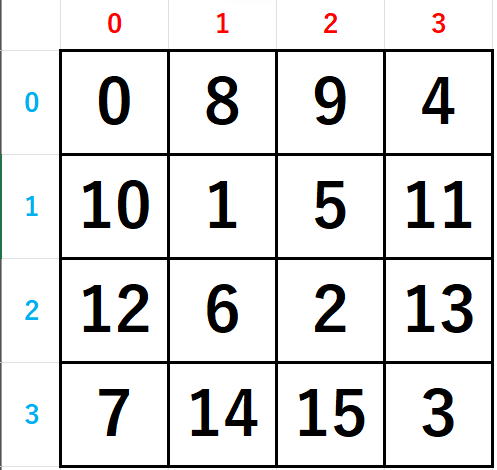
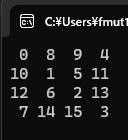
0 8 9 4
10 1 5 11
12 6 2 13
7 14 15 3
)
(
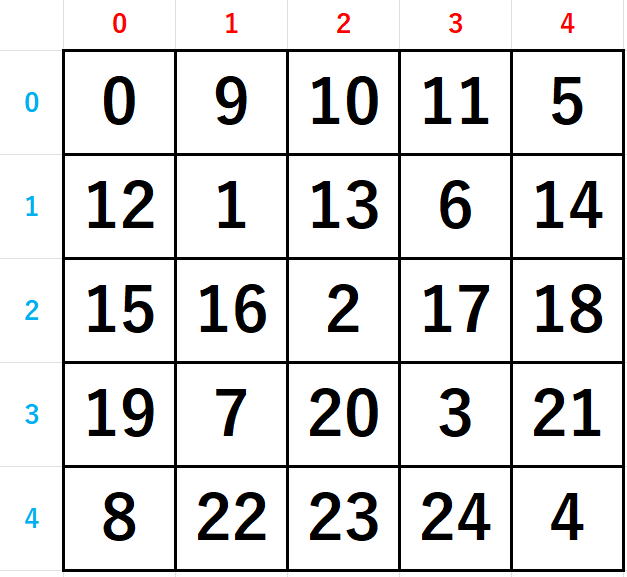
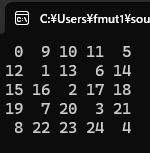
0 9 10 11 5
12 1 13 6 14
15 16 2 17 18
19 7 20 3 21
8 22 23 24 4
)
(
0 12 13 14 15 6
16 1 17 18 7 19
20 21 2 8 22 23
24 25 9 3 26 27
28 10 29 30 4 31
11 32 33 34 35 5
)
(
0 13 14 15 16 17 7
18 1 19 20 21 8 22
23 24 2 25 9 26 27
28 29 30 3 31 32 33
34 35 10 36 4 37 38
39 11 40 41 42 5 43
12 44 45 46 47 48 6
)
(
0 16 17 18 19 20 21 8
22 1 23 24 25 26 9 27
28 29 2 30 31 10 32 33
34 35 36 3 11 37 38 39
40 41 42 12 4 43 44 45
46 47 13 48 49 5 50 51
52 14 53 54 55 56 6 57
15 58 59 60 61 62 63 7
)
(
0 17 18 19 20 21 22 23 9
24 1 25 26 27 28 29 10 30
31 32 2 33 34 35 11 36 37
38 39 40 3 41 12 42 43 44
45 46 47 48 4 49 50 51 52
53 54 55 13 56 5 57 58 59
60 61 14 62 63 64 6 65 66
67 15 68 69 70 71 72 7 73
16 74 75 76 77 78 79 80 8
)
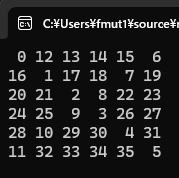
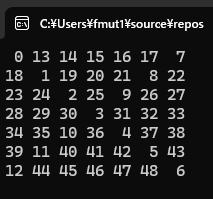
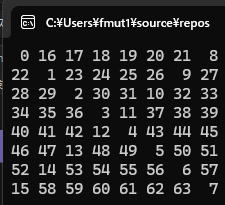
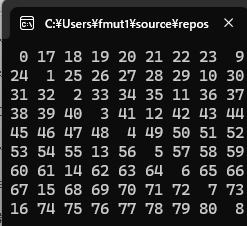
コードの1行1行に入る前に上に書いてある4次から8次までの実験結果をよく観察してください。
すべて同じ特徴を持っています。
それは、偶数のときには対角線と逆対角線が交差しないのに対して、
奇数のときには中央で交差している点です。
それで、私の場合には偶数と奇数に場合分けをしてプログラムを組んでいましたが、
仮屋崎さんの場合には
void 2次座標生成() {//y横座標とx縦座標生成
int i, j, c;
for (i = 0; i < n; i++) {
for (j = 0; j < n; j++) {
a[i][j] = -1;
}
}
for (i = 0; i < n; i++) {
a[i][i] = i;
}
c = n - 1;
for (i = 0; i < n; i++) {
if (a[i][n - 1 - i] == -1) {
c++;
a[i][n
- 1 - i] = c;
}
}
for (i = 0; i < n; i++) {
for (j = 0; j < n; j++) {
if (a[i][j]
== -1) {
c++;
a[i][j] = c;
}
}
}
for (i = 0; i < n; i++) {
for (j = 0; j < n; j++) {
x[a[i][j]]
= j;
y[a[i][j]] = i;
}
}
}
をご覧になればわかるように場合分けをしていません。
偶数と奇数では中央で交差する、交差しないの違いがあるのに、
なぜ、同じコードで対応できるのでしょうか。
これはC言語講義からとった題材で、
for文の書き方が少し異なります。
int i, j, c;
for (i = 0; i < n; i++) {
for (j = 0; j < n; j++) {
a[i][j] = -1;
}
}
今まで学んで書き方では、
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
a[i][j] = -1;
}
}
でした。
C++はC言語を拡張したものなので、
C言語の書き方が許されます。
1972年に開発されたC言語構造化プログラミングの思想が大変しっかりしていました。
構造化プログラミングというととても難しそうに感じてしまいますが、
変数の適応範囲を関数内に限定して、
関数をプラモデルのように単純に結合させる方法を構造化プログラミングというのです。
今まで例示してきたものはすべて1か所のみの結合です。
プラモデルの場合は精々数か所というところですが、
1か所のみです。
出口と入り口が同じところにあります。

出口と入口が一か所のみの単純結合です。
変数の範囲が関数内に限定されているので、
独立部品の単純結合です。
独立の意味は変数の値が、
他の関数では変数の値を変更できないという意味です。
かつてのBASICは変数はC言語流に表現するとすべてグローバル変数でした。
1972年だと積んでいるメモリは現在のパソコンとくればたら1/1000000倍以下でしょう。
プログラミングとは少ないメモリとの格闘だったのです。
それなのにBASICはすべての変数がグローバル変数だったのです。
つまり、使っていなくても少ないメモリ上に変数のためのメモリ領域が与えられていたということです。
問題は、メモリの無駄遣いという点だけにあるのではありません。
BASICにもサブルーチン(部品=プラモデルのパーツ)という考え方はありました。
ところが、他のサブルーチンによって勝手に変数の中身が書き換えられてしまう可能性があり、
サブルーチンのみの開発に専念できません。
常に全体を見ていないとならないわけです。
しかも、BASICの場合GO TO文であちらこちらに飛んで複雑に繋がっていました。
結局常に全体を見ていなければならず、
分業など不可能な所業と言わざるを得ません。
スパゲッティプログラムと揶揄されていました。
C言語は最初から独立部品の単純結合=構造化プログラミングの思想が徹底していました。
そして、驚くべきことは本講義第11章で学ぶマルチスレッドプログラミングが組めたということです。
さらに、BASICが機械語へ1行1行翻訳していく方式インタプリタであったのに対して、
C言語は一括翻訳=コンパイル方式だったのです。
一度まとめて翻訳してあるので、
ファイルは実行ファイルと呼ばれ最速のプログラム言語の地位を確立したのです。
そして、現在でもC言語もC++も完全なコンパイラ(コンパイルするソフト)方式をとっていて、
最速言語の地位を失っていません。
BASICの名誉のために言っておくとVisaul Basicになった現在は、
構造化プログラミングになっており、コンパイル方式になっており、
決して劣った言語ではありません。
ワードやエクセルに最初から組み込まれた統合開発環境であり、
実用性は非常に高いと言えます。
ただ、マルチスレッドプログラミングが難しいという点と演算速度が遅い点では、
C言語やC++に軍配が上がります。
脱線して戻るつもりでしたが、少し大きくなってしまいましたので、
構造化プログラミングの思想を背景思想として知っていた方がよいので、
必要な話であったという位置づけで解説は次話からにします。
そこで、第6話への課題は偶数次では対角線と逆対角線が交差せず、
奇数次では交差するのに、
なぜ、一括して扱えるのかコード見て考えてください。